
自然言語処理(NLP)は、もはや一部の専門家だけの領域ではありません。
Pythonを使えば、誰でも簡単にNLPの世界に足を踏み入れることができます。
自動応答システムやSNS分析、さらには文章生成まで、NLPはあなたのビジネスを劇的に変える可能性を秘めているのです。
この記事では、専門知識ゼロの方でも理解できるように、NLPの基礎からPythonでの実装方法、そしてビジネスでの活用事例までをわかりやすく解説します。
NLPの力でビジネスの未来を切り拓く準備はできていますか?さあ、一緒にNLPの世界へ飛び込みましょう!
この記事を読んでほしい人
- Pythonを使った自然言語処理に興味がある方
- NLPでビジネスを改善したい方
- 最新のNLPトレンドを知りたい方
この記事でわかること
- Pythonを使ったNLPの実装方法
- NLPのビジネス活用事例
- 2024年のNLP最新トレンド
なぜ今、自然言語処理(NLP)が注目されているのか?

自然言語処理(NLP)とは、私たち人間が日常的に使っている言葉をコンピューターに理解させる技術のことです。
検索エンジンの検索結果表示やスマートスピーカーの音声認識、機械翻訳、チャットボットによる自動応答など、NLPはすでに私たちの生活のさまざまな場面で活躍しています。
近年、AI技術の進化とビッグデータの普及により、NLPは目覚ましい発展を遂げました。
特に、「GPT-3」と呼ばれる大規模言語モデルは、人間が書いたような自然な文章を生成できることから、世界中に大きな衝撃を与えたことは記憶に新しいです。
NLPは、ビジネスの効率化や顧客体験の向上に大きく貢献できる可能性を秘めています。
たとえば、顧客からの問い合わせ対応を自動化するチャットボットや、SNSの投稿を分析して顧客のニーズを把握するマーケティングツールなど、NLPの応用範囲は多岐にわたり、今、NLPがビジネス界から熱い視線を浴びているのです。
Pythonで始める自然言語処理(NLP)入門

Pythonは、シンプルでわかりやすい文法と、豊富なライブラリ(便利なツールの集まり)の存在から、NLPの開発に最適な言語として人気を集めています。
NLPの代表的なライブラリには、以下のようなものがあります。
- NLTK:自然言語処理の定番ライブラリで初心者向けのチュートリアルやサンプルコードが豊富に用意されている
- spaCy:高速かつ高精度な自然言語処理を実現するライブラリ。実用的なアプリケーション開発に適している
- Gensim:トピックモデルや単語埋め込みなど、テキストデータの分析に特化したライブラリ
- Transformers:最新の深層学習モデル(BERT、GPTなど)を簡単に利用できるライブラリ
これらのライブラリを活用することで、Pythonで手軽にNLPの実装を始めることが可能です。
Pythonで自然言語処理(NLP)に関わる手法を実装

ここからは、Pythonで自然言語処理に関わる実装方法を解説していきます。
実装する前の前処理
まずは、細かな前処理が必要になります。
正規化
日本語には「2」と「2」、「ネコ」と「ネコ」など半角文字と全角文字があります。これらが混ざっていると、同じ意味なのに違う単語IDに振り分けられてしまうことが起こります。
それを防ぐために単語辞書を作るのと同時に、または分かち書きする前に正規化しましょう。
上のPyPiリンクのライブラリは、半角や全角文字を統一してくれる。便利な機能をもっています。
絵文字
絵文字も除去する必要がある場合があります。
上のPyPiリンクのライブラリは、絵文字を取り扱えるようにしてくれる便利な機能をもっています。
Stop Word
Stop Wordとは、全文検索などで一般的すぎて検索の邪魔になる単語をいいます。英語なら「The」や「a」など日本語なら「て」「に」「を」「は」などです。これらを取り除くことで、計算量の節約、学習精度を上げることができます。
ただ、あくまで全文検索、つまり検索エンジンのアルゴリズムからきているので、100%自然言語処理の学習において、正しいとは言い切れません。
なぜなら、「私は今日朝10時に起きた。」こんな文があり、「私に今日を朝10時に起きた。」や「私を今日は朝10時に起きた。」になると不自然な文になります。いろいろな考え方ややり方があると思いますが、とりあえずStop Wordの除去をPythonで実装してみましょう。
品詞ごとに分類
続いて品詞、例えば「名詞」「形容詞」「動詞」に絞って分類してみます。感情分析や、レコメンドシステムを作る際に便利です。
MeCabで形態素解析の実装
まずは適当なスクリプトファイルにコードを書いて形態素解析を出力してみます。

デフォルトの設定では以下のように出力されます。


他にも、オプション機能として4種類程の出力フォーマットを呼び出すことができます。「4種類程」と言った理由は、標準で用意されているオプションの4種類以外にユーザーがフォーマットを自由に定義できるようになっているからです。詳しくはMeCab公式の出力フォーマットをご参照ください。では4種類のオプションをそれぞれ見ていきましょう。
分かち書きオプション
分かち書きとは、文章の単語を空白で区切ることと言われています。では実際に「MeCab.Tagger()」の引数にオプションを追加して実行してみます。
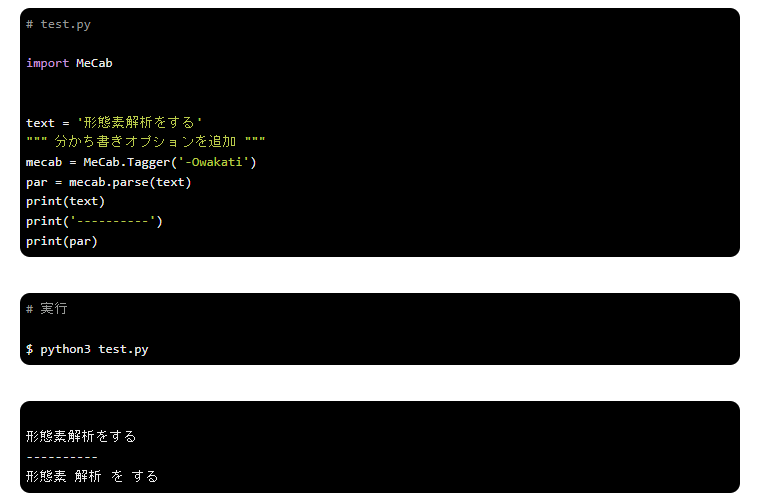
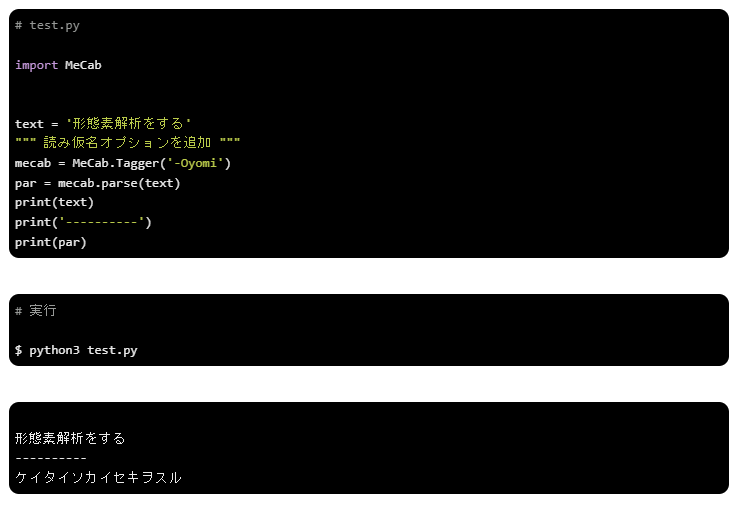
振り仮名オプション
振り仮名オプションを使うと、文字に対しての読み仮名を出力します。
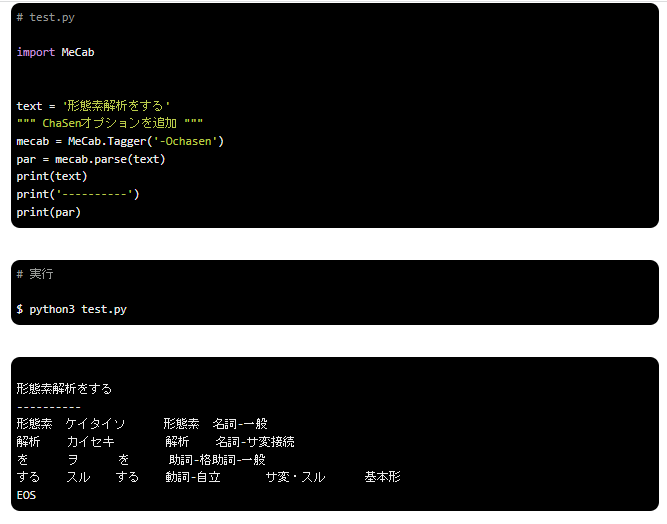
ChaSen(茶筌)オプション
ChaSenとは、茶筌システムとも呼び、奈良先端科学技術大学院大学情報科学研究科自然言語処理学講座(松本研究室)が保持する、形態素解析ソフトウェアの事です。その茶筌の解析器を使用して出力することができます。
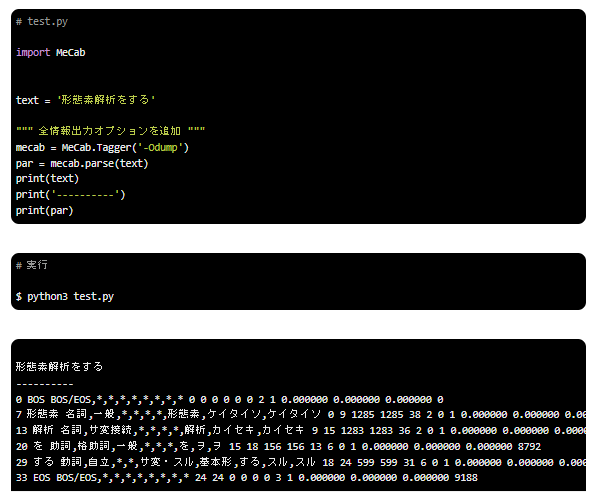
各単語の詳細情報を出力する
このオプションは単語に含まれる全情報を出力することができます。
mecab-ipadic-NEologdオプション
このオプションは、MeCab導入時に設定する、「新語」が適用されている辞書を使用する方法です。
MeCabのコマンドオプション「-d/usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd」と同じように「MeCab.Tagger()」の引数にそのまま渡します。
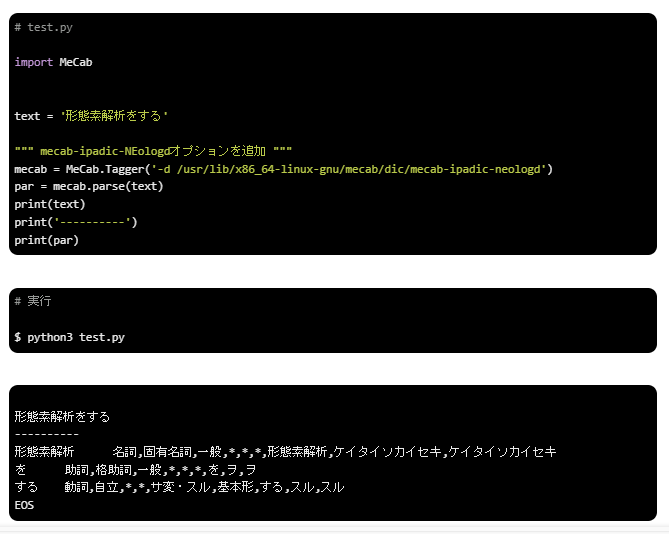
今まで「形態素」と「解析」で分割されていましたが、1つの名詞として「形態素解析」が出力されるようになりました。
文章をベクトル化する(Baf of Words)
それでは文章をベクトル化してプログラムで処理できるかたちに変換してみましょう。ベクトル化する技術には様々な方法がありますが、今回は最も基本的なBag of Wordsという手法をご紹介します。
Baf of Words
下記のような4つ文章がある状態を考えます。
A:私は猫が好きです
B:私は猫が嫌いです
C:私は犬が好きです
D:私は犬が嫌いです
これらの文章をそれぞれ形態素に分解します。
=Pythonコード====
import MeCab
wakati=MeCab.Tagger(“-Owakati”)
sentence_list = [“私は猫が好きです”, “私は猫が嫌いです”, “私は犬が好きです”, “私は犬が嫌いです”]
sentence_wakati_list = [wakati.parse(i).split() for i in sentence_list]
print(sentence_wakati_list)
==============
=出力結果=======
[[‘私’, ‘は’, ‘猫’, ‘が’, ‘好き’, ‘です’],[‘私’, ‘は’, ‘猫’, ‘が’, ‘嫌い’, ‘です’],[‘私’, ‘は’, ‘犬’, ‘が’, ‘好き’, ‘です’],[‘私’, ‘は’, ‘犬’, ‘が’, ‘嫌い’, ‘です’]]
==============
形態素に分解すると下記のようになります。
A:私 / は / 猫 / が / 好き / です
B:私 / は / 猫 / が / 嫌い / です
C:私 / は / 犬 / が / 好き / です
D:私 / は / 犬 / が / 嫌い / です
ここでそれぞれの文章の中身に注目してみると、「私」「は」「猫」「犬」「が」「好き」「嫌い」「です」という8つの形態素で構成されていることがわかります。縦軸に文章、横軸にそれぞれの文の中にどの形態素が含まれているかを「0」又は「1」でフラグ付けしたマトリクスになります。
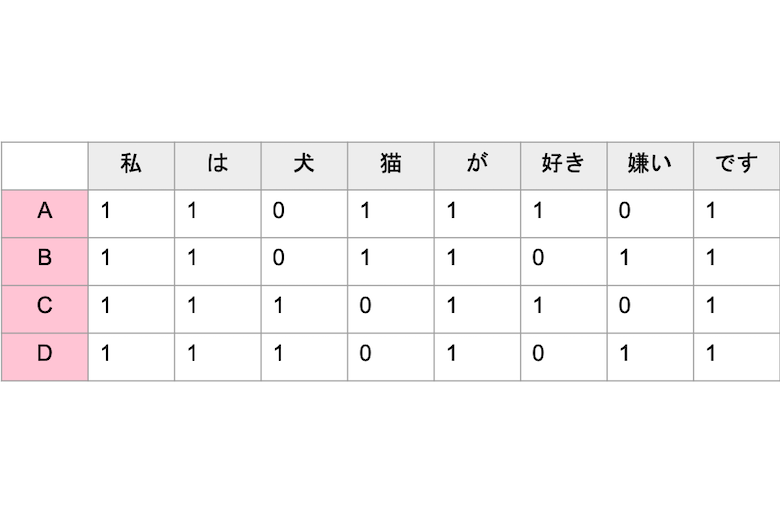
これが最も簡単なBag of Wordsの形です。Pythonでは下記を実行することでBag of Wordsを作成することができます。
=Pythonコード====
import numpy as np
word_to_index = {}
index_to_word = {}
for s in sentence_wakati_list:
for w in s:
if w not in word_to_index:
new_index = len(word_to_index)
word_to_index[w] = new_index
index_to_word[new_index] = w
corpus = np.zeros((len(sentence_wakati_list), len(word_to_index)))
for i, s in enumerate(sentence_wakati_list):
for w in s:
corpus[i, word_to_index[w]] = 1
==============
Bag of Wordsでできること
Bag of Wordsを作成したことで、文章をベクトルに変換することができました。ベクトルに変換することでプログラム上での処理が可能になります。例えば文章間の類似度を定量的に計算することができます。
A:私は猫が好きです
B:私は猫が嫌いです
C:私は犬が好きです
D:私は犬が嫌いです
再度上記の文章を例に「AとB」の類似度「AとC」の類似度「AとD」の類似度を計算します。類似度の計算にはcos類似度という方法を使用します。
=Pythonコード====
def cos_sim(x, y):
return np.dot(x, y) / (np.sqrt(np.sum(x**2)) * np.sqrt(np.sum(y**2)))
for i, v in enumerate([“B”, “C”, “D”]):
per = cos_sim(corpus[0], corpus[i + 1])
print(v + “:” + f”{per:.2}”)
==============
=出力結果=======
B:0.83
C:0.83
D:0.67
==============
・AとBの類似度:0.83
・AとCの類似度:0.83
・AとDの類似度:0.66
このような結果になりました。文章をみてもわかるように「AとB」「AとC」は異なる単語が1つだけですが、「AとD」は異なる単語が2つ存在しています。従って「AとD」が一番類似度が低いという結果になっています。このように文章をベクトル化することで定量的に文章の類似度を計算することができます。
BERTの実装方法
BERTが実装された背景には、音声認識サービスの普及と検索クエリの多様化が挙げられます。現在、検索時に利用されているデバイスの主流はスマートフォンであると言えるでしょう。
例えば「電気をつけて」と指示した場合に、音声認識サービスが指示を認識して実行してくれます。このような生活における自然言語による指示は複雑化しやすい傾向にあります。そのため、文脈を理解し、複雑化した指示にも対応していけるようなモデルが実装されたと言えます。
BERTの使い方
BERTを活用していく上で、事前学習の内容をしっかりと把握することが重要になってきます。明確に事前学習の内容を把握している場合には、ファインチューニング時の入力シーケンスの形式やどのような学習をさせるのかという判断を下しやすくなります。
BERTを使うことによって、検索したクエリに対してより精度の高い検索結果を得ることが可能なため、ユーザーにとっても大きなメリットがあると言えます。
Pythonを用いて日本語タスクでBERTを実装する際の注意点
Pythonを用いてBERTを実装する際には、BERT自体が巨大なモデルであるという点に注意しなければなりません。BERTは巨大なモデルである為、学習に対して多くの時間を要します。また、事前学習などにおいて、大量のデータが必要とされます。そのため、学習に対して多くの時間が必要な上、大きなメモリ量が必要とされる点など注意が必要です。
一般に配布されているBERTモデルにおいて、精度を上げる目的でパラメータを増やした場合、一定基準を超過すると精度が落ちてしまうといった点にも注意しなければなりません。
また、日本語タスクでBARTを扱う際は、単語分割にも注意が必要です。オリジナルのBARTでは多言語に対応していますが、ほぼ文字単位での単語分割になってしまいます。そのため、形態素解析器を用いるのが一般的です。
【2024年】NLPの最新トレンド

この章では、【2024年】NLPの最新トレンドをご紹介します。
- 大規模言語モデルの進化
- 少ないデータで学習できるモデルの開発
- マルチモーダルNLPの台頭
最新トレンドを押さえてNLPを活用しましょう。
大規模言語モデルの進化
GPT-3に代表される大規模言語モデルは、2024年も進化を続けています。
より大規模なデータで学習されたモデルが登場し、文章生成能力や言語理解能力がさらに向上しています。
少ないデータで学習できるモデルの開発
従来のNLPモデルは、大量の学習データが必要でしたが、近年では、少ないデータでも高精度な結果を出せるモデルの開発が進んでいます。
これにより、特定の分野やタスクに特化したNLPモデルを、より手軽に作成できるようになりました。
マルチモーダルNLPの台頭
マルチモーダルNLPとは、テキストだけでなく、画像や音声など、複数の種類の情報を組み合わせて処理する技術です。
たとえば、画像の内容を説明する文章を生成したり、音声から感情を分析したりできます。
NLPでビジネスを加速させる!

ここでは、NLPがビジネスにもたらす具体的な変革を見ていきましょう。
- 顧客対応の効率化:チャットボットが変えるコミュニケーション
- マーケティングの高度化:顧客の声から戦略を導き出す
- 業務プロセスの自動化:ルーティンワークからの解放
- 自然言語処理(NLP)で実現する未来
自然言語処理(NLP)は、もはや研究室の中だけの話ではありません。
顧客対応からマーケティング、社内業務の効率化まで、ビジネスのさまざまな場面でその力を発揮しています。
顧客対応の効率化:チャットボットが変えるコミュニケーション
NLPを活用したチャットボットは、顧客からの問い合わせ対応を自動化し、大幅な効率化を実現します。
よくある質問への回答や簡単な手続きを自動で行うことで、人間の担当者はより複雑な問題や個別対応に集中できるようになり、顧客満足度の向上と業務コストの削減を同時に達成することが可能です。
マーケティングの高度化:顧客の声から戦略を導き出す
NLPは、貴重な情報が眠っているSNSの投稿や顧客からのフィードバックのテキストデータを分析し、顧客のニーズや感情を把握することを可能にします。
たとえば、新商品の評判や競合製品に対する意見を分析することで、マーケティング戦略の改善や新製品開発に役立てることが可能です。
業務プロセスの自動化:ルーティンワークからの解放
NLPは、契約書や報告書などの文書の自動要約や、メールの自動分類など、これまで人間が行っていたルーティンワークを自動化する力をもっています。
これにより、従業員はより創造的な業務に時間を割くことができ、生産性の向上や労働環境の改善につながるのです。
自然言語処理(NLP)で実現する未来

ここでは、NLPが切り拓く未来の具体的な姿をいくつか紹介します。
- 医療分野:AIドクターが診断をサポート
- 教育分野:パーソナライズされた学習体験
- 金融分野:市場予測とリスク管理の高度化
- エンターテイメント分野:新しい創造体験
自然言語処理(NLP)は、私たちの生活やビジネスを大きく変える可能性を秘めています。
医療分野:AIドクターが診断をサポート
NLPを活用した電子カルテの自動要約や診断支援システムは、医療現場の負担軽減や診断精度の向上に貢献します。
膨大な医学論文を解析し、最新の医療情報を医師に提供することも可能です。
教育分野:パーソナライズされた学習体験
NLPは、個々の生徒の学習状況や理解度に合わせて、最適な教材や学習プランを提供する個別学習支援システムを実現します。
また、自動採点システムは教師の負担を軽減し、よりきめ細やかな指導を可能にします。
金融分野:市場予測とリスク管理の高度化
NLPは、金融市場の分析や不正検知システムなど、金融業務の効率化やリスク管理に活用できます。
たとえば、ニュース記事やSNSの情報を分析することで、市場の動向を予測し、投資戦略に役立てられます。
エンターテイメント分野:新しい創造体験
NLPは、作曲やゲームシナリオ生成など、新しいエンターテイメント体験の創出に貢献します。
たとえば、AIが小説や詩を創作したり、ユーザーの好みや感情に合わせた音楽を生成したりすることも可能です。
自然言語処理(NLP)に関するよくある質問

ここからは、自然言語処理(NLP)に関するよくある質問にMattockが回答していきます。
- Q1. NLPを日本語で何といいますか?
- Q2. 自然言語処理の4つのステップは?
- Q3. NLPの具体例は?
- Q4. 自然言語処理とはどういう意味ですか?
この章で自然言語処理(NLP)についての疑問を少しでも解消しておきましょう。
Q1. NLPを日本語で何といいますか?
NLPは日本語で「自然言語処理」といいます。
Q2. 自然言語処理の4つのステップは?
自然言語処理のおもなステップは以下の4つです。
- 形態素解析:文章を単語などの最小単位に分割し、品詞を特定する。
- 構文解析:単語間の関係性を解析し、文の構造を明らかにする。
- 意味解析:文の意味や意図を理解する。
- 文脈解析:前後の文脈を考慮して、文の意味をより深く理解する。
Q3. NLPの具体例は?
NLPの具体例としては、下記のようなものが挙げられます。
- 機械翻訳:Google翻訳など
- 検索エンジン:Google検索など
- チャットボット:カスタマーサポートなど
- 音声認識:SiriやAlexaなど
Q4. 自然言語処理とはどういう意味ですか?
自然言語処理とは、人間が日常的に使っている言葉をコンピュータに理解させ、処理させる技術のことです。
まとめ|自然言語処理(NLP)でビジネスチャンスを掴もう!
この記事では、Pythonを使った自然言語処理(NLP)の基礎と、最新のトレンド、そしてビジネス活用事例を紹介しました。
NLPは、私たちの生活やビジネスに革新をもたらす可能性を秘めた、非常にエキサイティングな分野です。
ベトナムオフショア開発でNLPシステムを構築しませんか?
弊社では、ベトナムオフショア開発を活用したNLPシステムの構築を支援しています。
経験豊富なエンジニアが、お客様のニーズに合わせた最適なシステムを開発します。
- ラボ型契約:開発チームを一定期間確保し、柔軟に開発を進められます。
- 業務効率化コンサルティング:NLPを活用した業務効率化のノウハウを提供し、お客様の課題解決をサポートします。
NLPシステムの構築にご興味のある方は、ぜひお気軽にご相談ください。

